개요
파이토치의 차세대 2시리즈 릴리스를 향한 첫 걸음인 파이토치 2.0을 소개합니다. 지난 몇 년 동안 파이토치는 파이토치 1.0부터 최신 1.13까지 혁신과 반복을 거듭해왔으며, 리눅스 재단의 일부인 새로 설립된 파이토치 재단으로 이전했습니다.
파이토치의 가장 큰 강점은 놀라운 커뮤니티 외에도 최고 수준의 파이썬 통합, 명령형 스타일, API 및 옵션의 단순성을 계속 유지한다는 것입니다. PyTorch 2.0은 동일한 열성적인 모드 개발 및 사용자 경험을 제공하는 동시에, 내부적으로 컴파일러 수준에서 PyTorch가 작동하는 방식을 근본적으로 변경하고 강화했습니다. 더 빠른 성능과 동적 모양 및 분산 지원을 제공할 수 있게 되었습니다.
아래에서 파이토치 2.0이 무엇인지, 어디로 나아가고 있는지, 그리고 가장 중요한 지금 시작하는 방법(예: 튜토리얼, 요구사항, 모델, 일반적인 FAQ)을 이해하는 데 필요한 모든 정보를 찾을 수 있습니다. 아직 배우고 개발해야 할 것이 많지만 더 나은 2.0을 만들기 위해 커뮤니티의 피드백과 기여를 기다리고 있으며, 1.0을 성공적으로 만들어주신 모든 분들께 감사드립니다.
파이토치 2.x: 더 빠르고, 더 파이써닉하며, 그 어느 때보다 동적입니다.
오늘, 파이토치 성능을 새로운 차원으로 끌어올리고 파이토치의 일부가 C++에서 파이썬으로 다시 이동하기 시작하는 기능인 torch.compile을 발표합니다. 저희는 이것이 파이토치에서 상당히 새로운 방향이라고 생각하며, 따라서 2.0이라고 부릅니다. torch.compile은 완전히 추가되는(그리고 선택적인) 기능이며, 따라서 2.0은 정의상 100% 이전 버전과 호환됩니다.
torch.compile을 뒷받침하는 새로운 기술로는 TorchDynamo, AOTAutograd, PrimTorch 및 TorchInductor가 있습니다.
- TorchDynamo는 Python 프레임 평가 훅을 사용하여 PyTorch 프로그램을 안전하게 캡처하며, 안전한 그래프 캡처에 대한 5년간의 연구 개발의 결과로 탄생한 중요한 혁신입니다.
- AOTAutograd는 파이토치의 오토그래드 엔진에 미리 역추적을 생성하기 위한 추적 오토디프를 오버로드합니다.
- PrimTorch는 2000개 이상의 PyTorch 연산자를 개발자가 완전한 PyTorch 백엔드를 구축하기 위해 타깃으로 삼을 수 있는 250개 정도의 폐쇄된 기본 연산자 집합으로 표준화합니다. 이를 통해 파이토치 기능이나 백엔드 작성의 장벽이 크게 낮아집니다.
- TorchInductor는 여러 가속기 및 백엔드를 위한 빠른 코드를 생성하는 딥 러닝 컴파일러입니다. NVIDIA GPU의 경우, 이 컴파일러는 OpenAI Triton을 핵심 빌딩 블록으로 사용합니다.
TorchDynamo, AOTAutograd, PrimTorch, TorchInductor는 파이썬으로 작성되었으며 동적 모양(즉, 재컴파일 없이 다양한 크기의 텐서를 전송하는 기능)을 지원하므로 유연하고 쉽게 해킹할 수 있으며 개발자와 공급업체의 진입 장벽을 낮춥니다.
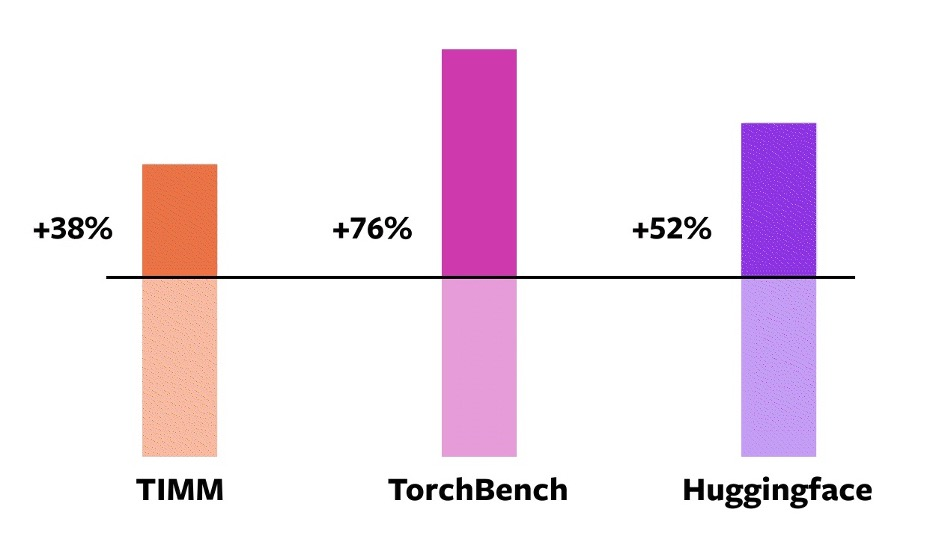
이러한 기술을 검증하기 위해 다양한 머신 러닝 영역에 걸쳐 163개의 다양한 오픈 소스 모델을 사용했습니다. 이미지 분류, 객체 감지, 이미지 생성, 언어 모델링, 질의응답, 시퀀스 분류, 추천 시스템, 강화 학습과 같은 다양한 자연어 처리(NLP) 작업을 포함하도록 이 벤치마크를 신중하게 구축했습니다. 벤치마크는 세 가지 범주로 나뉩니다:
- Hugging Face Transformers의 46개 모델(NLP)
- TIMM의 61개 모델: 로스 와이트먼의 SOTA 파이토치 이미지 모델 컬렉션(Image)
- TorchBench의 56개 모델: github에서 엄선된 인기 코드 베이스 세트(인기 벤치마크??)
이러한 오픈 소스 모델을 래핑하는 torch.compile 호출을 추가하는 것 외에는 수정하지 않았습니다.
그런 다음 이러한 모델 전반에 걸쳐 속도 향상을 측정하고 정확도를 검증합니다. 속도 향상은 데이터 유형에 따라 달라질 수 있으므로 float32와 자동 혼합 정밀도(AMP) 모두에서 속도 향상을 측정합니다. 실제로는 AMP가 더 일반적이기 때문에 0.75 * AMP + 0.25 * float32의 고르지 않은 가중 평균 속도 향상을 보고합니다.
이 163개의 오픈 소스 모델에서 torch.compile은 93%의 시간 동안 작동하며, NVIDIA A100 GPU에서 훈련할 때 43% 더 빠르게 실행됩니다. Float32 정밀도에서는 평균 21% 더 빠르게 실행되며 AMP 정밀도에서는 평균 51% 더 빠르게 실행됩니다.
주의: NVIDIA 3090과 같은 데스크톱급 GPU에서는 A100과 같은 서버급 GPU보다 속도가 느린 것으로 측정되었습니다. 현재 기본 백엔드인 토치인덕터는 CPU와 NVIDIA 볼타 및 암페어 GPU를 지원합니다. (아직) 다른 GPU, xPU 또는 구형 NVIDIA GPU는 지원하지 않습니다.
사용해보기: torch.compile은 개발 초기 단계에 있습니다. 오늘부터 nightly 바이너리에서 torch.compile을 사용해 볼 수 있습니다. 2023년 3월 초에 첫 번째 안정적인 2.0 릴리스가 출시될 예정입니다.
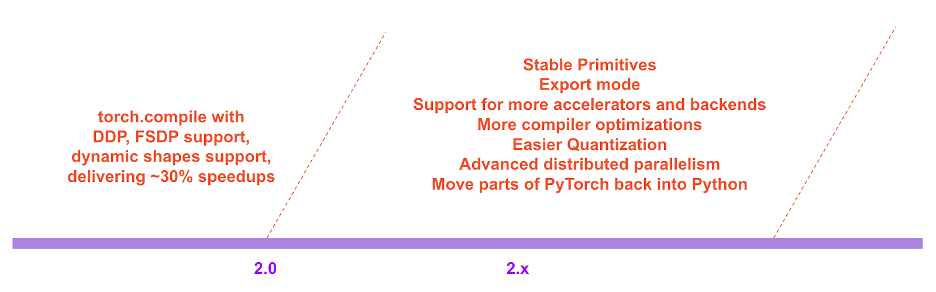
파이토치 2.x의 로드맵에서는 성능과 확장성 측면에서 컴파일 모드를 더욱 발전시키고자 합니다. 오늘 컨퍼런스에서 말씀드린 것처럼 이 작업 중 일부는 현재 진행 중입니다. 이 작업 중 일부는 아직 시작되지 않았습니다. 이 작업 중 일부는 저희도 기대하고 있지만 자체적으로 수행할 수 있는 대역폭이 없는 작업이기도 합니다. 기여에 관심이 있으시다면 이번 달부터 시작되는 '엔지니어에게 물어보세요: 2.0 라이브 Q&A 시리즈'(자세한 내용은 이 게시물 끝에 나와 있습니다) 및/또는 Github/포럼을 통해 저희와 함께 이야기를 나눠보세요.
사용자 후기 파이토치 사용자들이 새로운 방향에 대해 어떤 의견을 남겼는지 알아보세요:
실뱅 거거, HuggingFace 트랜스포머의 메인 유지관리자:
"코드 한 줄만 추가하면 PyTorch 2.0은 트랜스포머 모델 훈련 속도를 1.5배에서 2.2배까지 높일 수 있습니다. 이는 혼합 정밀 훈련이 도입된 이래 가장 흥미로운 일입니다!"
PyTorch 에코시스템 내에서 가장 큰 비전 모델 허브 중 하나인 TIMM의 기본 유지 관리자인 Ross Wightman:
"코드 변경 없이 추론 및 훈련 워크로드를 위한 대부분의 TIMM 모델에서 바로 작동합니다."
루카 안티가(Luca Antiga), Lightning AI의 CTO이자 PyTorch Lightning의 주요 유지 관리자 중 한 명
"PyTorch 2.0은 딥 러닝 프레임워크의 미래를 구현합니다. 사용자 개입 없이도 PyTorch 프로그램을 캡처하고 장치에서 엄청난 속도 향상과 프로그램 조작을 즉시 수행할 수 있다는 점은 AI 개발자에게 완전히 새로운 차원의 가능성을 열어줍니다."
동기 부여
파이토치의 철학은 항상 유연성과 해킹 가능성을 최우선 순위로 삼고, 성능은 그 다음 순위로 두는 것이었습니다. 우리는 다음을 위해 노력했습니다:
- 고성능의 열성적인 실행
- 파이써닉한 내부
- 분산, 자동미분, 데이터 로딩, 액셀러레이터 등을 위한 좋은 추상화.
2017년 파이토치 출시 이후 하드웨어 가속기(예: GPU)의 연산 속도는 약 15배, 메모리 액세스 속도는 약 2배 빨라졌습니다. 따라서 고성능 실행을 유지하기 위해 파이토치 내부의 상당 부분을 C++로 옮겨야 했습니다. 내부를 C++로 옮기면 해킹 가능성이 줄어들고 코드 기여에 대한 진입 장벽이 높아집니다.
첫날부터 저희는 열성적인 실행의 성능 한계를 알고 있었습니다. 2017년 7월, 저희는 파이토치용 컴파일러를 개발하기 위한 첫 번째 연구 프로젝트를 시작했습니다. 컴파일러는 파이토치 프로그램을 빠르게 만들어야 했지만, 파이토치 경험을 희생해서는 안 되었습니다. 우리의 핵심 기준은 연구자들이 다양한 탐색 단계에서 사용하는 동적 모양과 동적 프로그램을 지원하는 등 특정 종류의 유연성을 유지하는 것이었습니다.
기술 개요
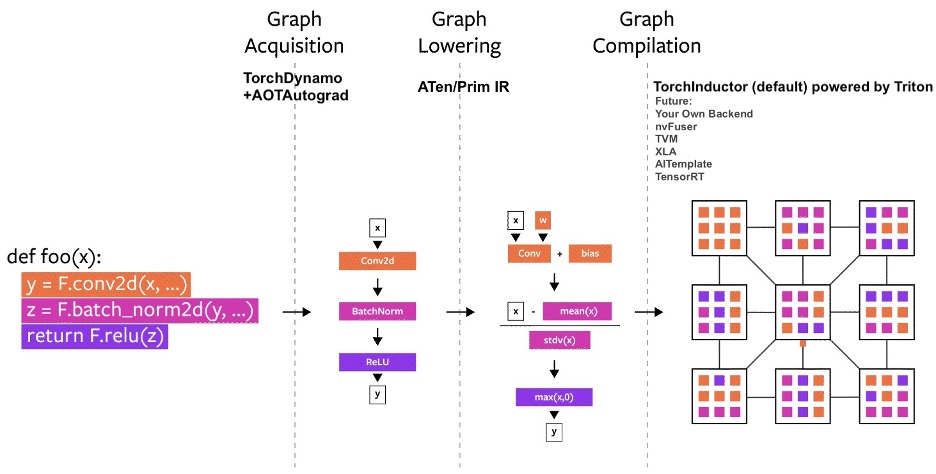
지난 몇 년 동안 저희는 PyTorch 내에서 여러 컴파일러 프로젝트를 구축했습니다. 컴파일러를 세 부분으로 나눠보겠습니다:
- 그래프 획득(Graph Acquisition)
- 그래프 낮추기(Graph Lowering)
- 그래프 컴파일(Graph Compilation)
파이토치 컴파일러를 구축할 때 그래프 획득은 가장 어려운 과제였습니다.
지난 5년 동안 우리는 torch.jit.trace, TorchScript, FX 추적, Lazy Tensors를 구축했습니다. 하지만 그 어느 것도 우리가 원하는 모든 것을 제공한다고 느끼지 못했습니다. 일부는 유연하지만 빠르지 않았고, 일부는 빠르지만 유연하지 않았으며, 일부는 빠르지도 유연하지도 않았습니다. 일부는 사용자 경험이 좋지 않았습니다(예: 조용히 잘못 작동하는 등). 토치스크립트는 유망했지만, 코드와 코드에 의존하는 코드를 크게 변경해야 했습니다. 코드를 크게 변경해야 한다는 점 때문에 많은 PyTorch 사용자가 시작하지 않았습니다.
TorchDynamo: Acquiring Graphs reliably and fast
올해 초, 저희는 프레임 평가 API라는 PEP-0523에 도입된 CPython 기능을 사용하는 접근 방식인 TorchDynamo에 대한 작업을 시작했습니다. 그래프 캡처에 대한 효과를 검증하기 위해 데이터 중심 접근 방식을 취했습니다. PyTorch로 작성된 7,000개 이상의 Github 프로젝트를 검증 세트로 사용했습니다. TorchScript와 다른 도구는 50%의 시간 동안 그래프를 캡처하는 데 어려움을 겪었고 종종 큰 오버헤드가 발생했지만, TorchDynamo는 원본 코드를 변경할 필요 없이 99%의 시간 동안 정확하고 안전하게, 그리고 오버헤드가 거의 발생하지 않는 그래프를 캡처했습니다. 이 순간 우리는 유연성과 속도 측면에서 수년 동안 어려움을 겪었던 장벽을 마침내 돌파했다는 것을 알았습니다.
TorchInductor: 정의별 실행 IR을 사용한 빠른 코드 생성
PyTorch 2.0을 위한 새로운 컴파일러 백엔드의 경우, 사용자들이 고성능 커스텀 커널을 작성하는 방식에서 영감을 얻어 점점 더 많은 사용자가 트리톤 언어를 사용하고 있습니다. 또한 파이토치와 유사한 추상화를 사용하고 파이토치의 광범위한 기능을 지원할 수 있을 만큼 범용적인 컴파일러 백엔드를 원했습니다. TorchInductor는 파이썬의 실행별 정의 루프 레벨 IR을 사용하여 PyTorch 모델을 GPU에서 생성된 트리톤 코드와 CPU에서 생성된 C++/OpenMP에 자동으로 매핑합니다. TorchInductor의 핵심 루프 레벨 IR에는 약 50개의 연산자만 포함되어 있으며, 파이썬으로 구현되어 쉽게 해킹하고 확장할 수 있습니다.
AOTAutograd: AUTOgrad를 미리 그래프에 재사용하기
PyTorch 2.0에서는 교육 속도를 높이고 싶었습니다. 따라서 사용자 수준의 코드를 캡처하는 것뿐만 아니라 역전파도 캡처하는 것이 중요했습니다. 또한 기존의 전투 테스트를 거친 PyTorch 오토그라드 시스템을 재사용하고 싶다는 생각도 들었습니다. AOTAutograd는 파이토치의 토치_디스패치 확장성 메커니즘을 활용하여 오토그라드 엔진을 통해 추적함으로써 역전파를 '미리' 캡처할 수 있습니다. 이를 통해 TorchInductor를 사용하여 전진 및 후진 패스를 모두 가속화할 수 있습니다.
PrimTorch: 안정적인 프리미티브 연산자
파이토치용 백엔드를 작성하는 것은 쉽지 않습니다. PyTorch에는 1200개 이상의 연산자가 있으며, 각 연산자에 대한 다양한 과부하를 고려하면 2000개 이상이 있습니다.
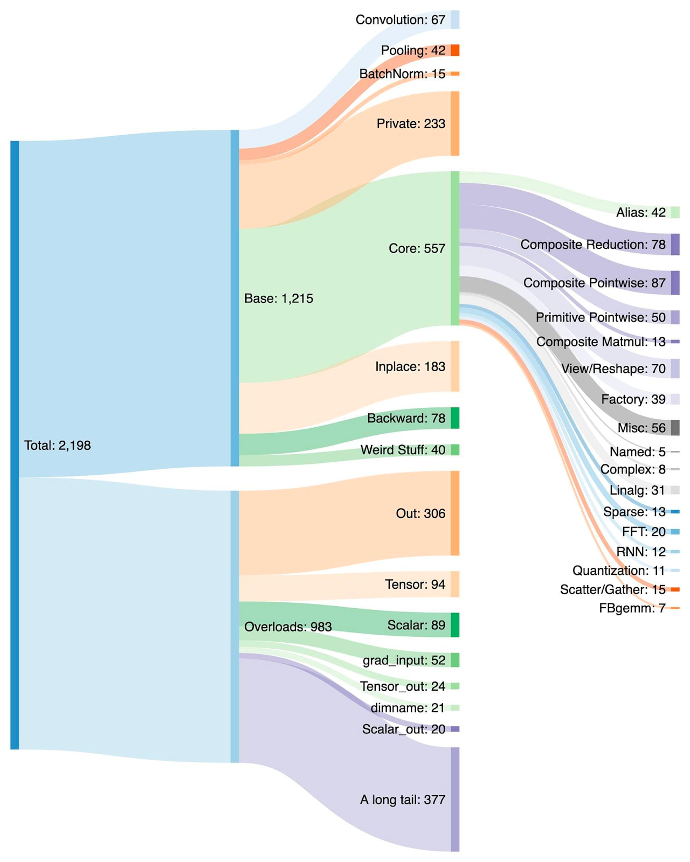
따라서 백엔드나 크로스 커팅 기능을 작성하는 것은 소모적인 작업이 됩니다. PrimTorch 프로젝트 내에서 우리는 더 작고 안정적인 연산자 집합을 정의하기 위해 노력하고 있습니다. PyTorch 프로그램은 이러한 연산자 집합으로 지속적으로 낮출 수 있습니다. 우리는 두 가지 연산자 집합을 정의하는 것을 목표로 합니다:
- 약 250개의 연산자가 있는 프라임 오퍼레이션은 상당히 낮은 수준입니다. 이들은 컴파일러에 적합하며, 좋은 성능을 얻으려면 다시 융합해야 할 정도로 낮은 수준이기 때문입니다.
- 약 750개의 표준 연산자가 포함된 ATen 운영체제는 있는 그대로 내보내기에 적합합니다. 이미 ATen 수준에서 통합된 백엔드 또는 Prim 운영체제와 같은 하위 수준 연산자 세트에서 성능을 복구하기 위한 컴파일이 없는 백엔드에 적합합니다.
아래 개발자/공급업체 경험 섹션에서 이 주제에 대해 자세히 설명합니다.
사용자 경험
모델을 래핑하고 컴파일된 모델을 반환하는 간단한 함수 torch.compile을 소개합니다.
compiled_model = torch.compile(model)
이 compiled_model은 모델에 대한 참조를 보유하고 forward 함수를 보다 최적화된 버전으로 컴파일합니다. 모델을 컴파일할 때 모델을 조정할 수 있는 몇 가지 노브를 제공합니다:
def torch.compile(
model: Callable,
*,
mode: Optional[str]= "default",
dynamic: bool= False,
fullgraph:bool= False,
backend: Union[str, Callable]= "inductor",
# advanced backend options go here as kwargs
**kwargs )-> torch._dynamo.NNOptimizedModule- 모드는 컴파일하는 동안 컴파일러가 최적화해야 하는 항목을 지정합니다.
- 기본 모드는 컴파일에 너무 오래 걸리거나 추가 메모리를 사용하지 않고 효율적으로 컴파일하려는 사전 설정입니다.
- 감소 오버헤드와 같은 다른 모드는 프레임워크 오버헤드를 훨씬 더 많이 줄이지만 추가 메모리를 조금 더 소모합니다. 최대 자동 조정은 생성 가능한 가장 빠른 코드를 제공하기 위해 오랜 시간 동안 컴파일을 시도합니다.
- dynamic은 동적 셰이프에 대한 코드 경로를 활성화할지 여부를 지정합니다. 특정 컴파일러 최적화는 동적 셰이프 프로그램에 적용할 수 없습니다. 동적 모양으로 컴파일할지 정적 모양으로 컴파일할지 명시하면 컴파일러가 더 최적화된 코드를 제공하는 데 도움이 됩니다.
- 풀그래프는 Numba의 nopython과 유사합니다. 전체 프로그램을 단일 그래프로 컴파일하거나 컴파일할 수 없는 이유를 설명하는 오류를 제공합니다. 대부분의 사용자는 이 모드를 사용할 필요가 없습니다. 성능에 매우 민감한 사용자라면 이 모드를 사용하세요.
- 백엔드는 사용할 컴파일러 백엔드를 지정합니다. 기본적으로 TorchInductor가 사용되지만 몇 가지 다른 컴파일러를 사용할 수 있습니다.

컴파일 환경은 기본 모드에서 가장 많은 이점과 유연성을 제공하도록 설계되었습니다. 다음은 각 모드에서 얻을 수 있는 기능에 대한 멘탈 모델입니다.
이제 실제 모델을 컴파일하고 실행하는 전체 예제(무작위 데이터 포함)를 살펴보겠습니다.
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()compiled_model(x)를 처음 실행하면 모델을 컴파일합니다. 따라서 실행하는 데 시간이 오래 걸립니다. 이후 실행은 빠릅니다.
Modes
컴파일러에는 컴파일된 모델을 다양한 방식으로 조정하는 몇 가지 사전 설정이 있습니다. 당신은 아마 프레임워크 오버헤드 때문에 느린 작은 모델을 실행하고 있을 수 있습니다. 또는 메모리에 거의 들어가지 않는 큰 모델을 실행하고 있을 수도 있습니다. 여러분의 필요에 따라 다른 모드를 사용할 수 있습니다.
# API NOT FINAL # default: optimizes for large models, low compile-time # and no extra memory usage torch.compile(model) # reduce-overhead: optimizes to reduce the framework overhead # and uses some extra memory. Helps speed up small models torch.compile(model, mode="reduce-overhead") # max-autotune: optimizes to produce the fastest model, # but takes a very long time to compile torch.compile(model, mode="max-autotune")속성 읽기 및 업데이트
모델 속성에 액세스하는 것은 eager 모드에서와 동일하게 작동합니다. 일반적인 경우와 마찬가지로 모델 속성(예: model.conv1.weight)에 액세스하거나 수정할 수 있습니다. 이는 코드 수정 측면에서 완전히 안전하고 건전합니다. TorchDynamo는 코드에 가드를 삽입하여 가정이 맞는지 확인합니다. 속성이 특정 방식으로 변경되면 TorchDynamo는 필요에 따라 자동으로 다시 컴파일하는 것을 알고 있습니다.
# optimized_model works similar to model, feel free to access its attributes and modify them optimized_model.conv1.weight.fill_(0.01) # this change is reflected in modelhooks
모듈 및 텐서 후크는 현재 완전히 작동하지는 않지만, 개발이 완료되면 곧 작동할 예정입니다.
Serialization
최적화된 모델 또는 모델의 상태 딕셔너리를 직렬화할 수 있습니다. 이 둘은 동일한 매개변수와 상태를 가리키므로 동등합니다.
torch.save(optimized_model.state_dict(), "foo.pt") # both these lines of code do the same thing torch.save(model.state_dict(), "foo.pt")현재 최적화된 모델을 직렬화할 수 없습니다. 개체를 직접 저장하려면 대신 모델 저장을 사용하세요.
torch.save(optimized_model, "foo.pt") # Error torch.save(model, "foo.pt") # WorksInference and Export
모델 추론의 경우, torch.compile을 사용하여 컴파일된 모델을 생성한 후 실제 모델을 제공하기 전에 몇 가지 워밍업 단계를 실행하세요. 이렇게 하면 초기 서빙 중 지연 시간 급증을 완화하는 데 도움이 됩니다.
또한, 보장되고 예측 가능한 지연 시간이 필요한 환경을 위해 전체 모델과 가드 인프라를 신중하게 내보내는 torch.export라는 모드를 도입할 예정입니다. 특히 데이터 종속적인 제어 흐름이 있는 경우, torch.export를 사용하려면 프로그램을 변경해야 할 수 있습니다.
# API Not Final exported_model = torch._dynamo.export(model, input) torch.save(exported_model, "foo.pt")아직 개발 초기 단계에 있습니다. 자세한 내용은 파이토치 컨퍼런스에서 내보내기 경로에 대한 강연을 들어보세요. 이번 달부터 시작되는 '엔지니어에게 물어보세요: 2.0 라이브 Q&A 시리즈'에서도 이 주제에 대해 자세히 알아볼 수 있습니다(자세한 내용은 이 게시물 말미에 나와 있습니다).
Debugging Issues
컴파일된 모드는 불투명하고 디버깅하기 어렵습니다. 다음과 같은 질문이 있을 것입니다:
- 컴파일 모드에서 프로그램이 충돌하는 이유는 무엇인가요?
- 컴파일 모드가 에지 모드만큼 정확하나요?
- 속도가 빨라지지 않는 이유는 무엇인가요?
컴파일 모드에서 오류나 충돌이 발생하거나 기계 정밀도 한계를 넘어선 열망 모드에서 발산되는 결과가 발생한다면 코드의 결함일 가능성은 거의 없습니다. 하지만 어떤 코드가 버그의 원인인지 파악하는 것은 유용합니다.
디버깅과 재현성을 돕기 위해 여러 가지 도구와 로깅 기능을 만들었으며, 그 중 눈에 띄는 기능이 하나 있습니다: 바로 미니파이어입니다.
축소기는 자동으로 표시되는 문제를 작은 코드 조각으로 줄입니다. 이 작은 코드 조각은 원래 이슈를 재현하며, 축소된 코드로 깃허브 이슈를 제출할 수 있습니다. 이렇게 하면 PyTorch 팀이 쉽고 빠르게 문제를 해결하는 데 도움이 됩니다.
기대한 만큼 속도가 빨라지지 않는다면 코드의 어느 부분에서 "그래프 중단"이 발생했는지 설명하는 torch._dynamo.explain 도구가 있습니다. 그래프 중단은 일반적으로 컴파일러가 코드 속도를 높이는 데 방해가 되며, 그래프 중단의 수를 줄이면 코드 속도가 빨라질 수 있습니다(어느 정도 반환이 감소하는 한도까지).
자세한 내용은 문제 해결 가이드에서 확인할 수 있습니다.
동적 모양
PyTorch 코드의 범용성을 지원하기 위해 무엇이 필요한지 살펴볼 때, 동적 셰이프를 지원하고 셰이프가 변경될 때마다 다시 컴파일하지 않고도 모델이 다양한 크기의 텐서를 사용할 수 있도록 하는 것이 핵심 요구 사항 중 하나였습니다.
현재 다이나믹 셰이프에 대한 지원은 제한적이며 빠르게 진행 중입니다. 안정적인 릴리스에서 모든 기능을 제공할 예정입니다. 동적 도형 지원은 dynamic=True 인수 뒤에 게이트되어 있으며, 기능 브랜치(심볼릭 셰이프)에서 더 많은 진전이 있으며, 이 브랜치에서는 TorchInductor를 사용하여 전체 심볼릭 셰이프를 사용한 훈련에서 BERT_pytorch를 성공적으로 실행했습니다. 동적 도형을 사용한 추론의 경우 더 많은 범위가 있습니다. 예를 들어 동적 도형이 유용한 일반적인 설정인 언어 모델을 사용한 텍스트 생성을 살펴보겠습니다.
모양이 4에서 256까지 동적으로 변경되는 경우에도 컴파일 모드가 최대 40%까지 일관되게 eager보다 성능이 뛰어나다는 것을 알 수 있습니다. 동적 도형을 지원하지 않는 경우 일반적인 해결 방법은 가장 가까운 2의 거듭제곱으로 패딩하는 것입니다. 하지만 아래 차트에서 볼 수 있듯이 이 경우 상당한 성능 오버헤드가 발생하고 컴파일 시간도 상당히 길어집니다. 또한 패딩을 올바르게 수행하기가 쉽지 않은 경우도 있습니다.
PyTorch 2.0의 컴파일 모드에서 동적 도형을 지원함으로써 최고의 성능과 사용 편의성을 얻을 수 있습니다.

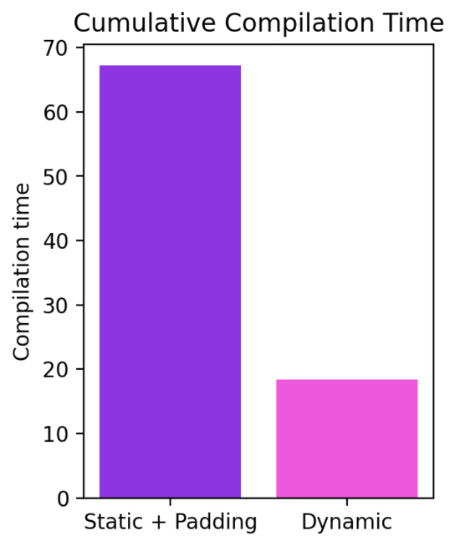
현재 작업은 매우 빠르게 발전하고 있으며, 인프라에 대한 근본적인 개선이 이루어질 때까지 일부 모델이 일시적으로 퇴보할 수 있습니다. 동적 도형에 대한 최신 업데이트는 여기에서 확인할 수 있습니다.
DISTRIBUTED
요약하자면, torch.distributed의 두 가지 주요 분산 래퍼는 컴파일 모드에서 잘 작동합니다.
분산데이터병렬(DDP)과 완전샤딩데이터병렬(FSDP)은 모두 컴파일 모드에서 작동하며, 이저 모드에 비해 향상된 성능과 메모리 활용도를 제공하지만, 몇 가지 주의 사항과 제한 사항이 있습니다.
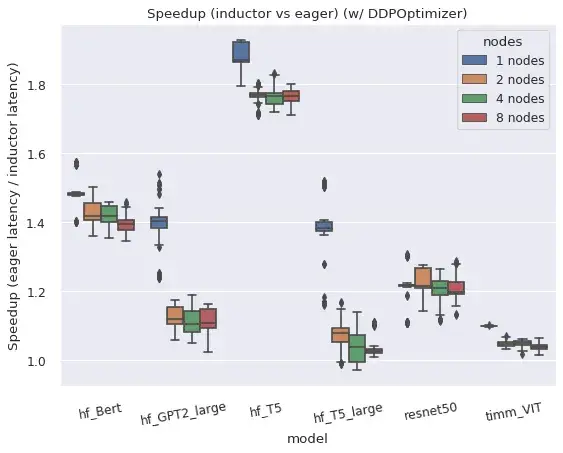 Speedups in AMP Precision
Speedups in AMP Precision
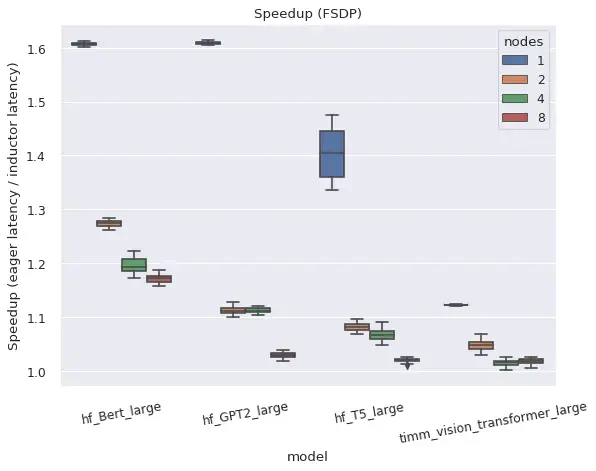

분산데이터병렬(DDP)
DDP는 올리듀스 통신을 역방향 계산과 중복하고, 더 작은 계층별 올리듀스 작업을 '버킷'으로 그룹화하여 효율성을 높이는 데 의존합니다. TorchDynamo에서 컴파일한 AOTAutograd 함수는 DDP와 순진하게 결합할 경우 통신 중복을 방지하지만, 각 '버킷'에 대해 별도의 하위 그래프를 컴파일하고 통신 작업이 하위 그래프 외부와 중간에서 이루어지도록 함으로써 성능을 회복할 수 있습니다. 컴파일 모드에서 DDP를 지원하려면 현재 static_graph=False가 필요합니다. DDP + TorchDynamo에 대한 접근 방식과 결과에 대한 자세한 내용은 이 게시물을 참조하세요.
완전 샤딩된 데이터 병렬(FSDP)
FSDP 자체는 "베타" 파이토치 기능이며, 어떤 서브모듈을 래핑할지 조정할 수 있고 일반적으로 더 많은 구성 옵션이 있기 때문에 DDP보다 시스템 복잡성이 더 높습니다.use_original_params=True 플래그로 구성한 경우 FSDP는 다양한 인기 모델에 대해 TorchDynamo 및 TorchInductor와 함께 작동합니다. 현재로서는 특정 모델 또는 구성과의 호환성 문제가 예상되지만 적극적으로 개선될 예정이며, 특정 모델에 대한 github 이슈가 접수되면 우선순위를 지정할 수 있습니다.
사용자는 auto_wrap_policy 인수를 지정하여 상태 샤딩에 사용되는 FSDP 인스턴스에서 함께 래핑할 모델의 서브모듈을 지정하거나, 수동으로 FSDP 인스턴스에서 서브모듈을 래핑할 수 있습니다. 예를 들어, 많은 변압기 모델은 각 '변압기 블록'을 별도의 FSDP 인스턴스로 래핑하여 한 번에 하나의 변압기 블록의 전체 상태만 구체화하면 잘 작동합니다. Dynamo는 각 FSDP 인스턴스의 경계에 그래프 중단을 삽입하여 순방향(및 역방향) 통신 작업이 그래프 외부에서 계산과 병렬로 이루어질 수 있도록 합니다.
서브모듈을 별도의 인스턴스로 래핑하지 않고 FSDP를 사용하는 경우, DDP와 유사하게 작동하지만 버켓팅이 없는 상태로 되돌아갑니다. 따라서 모든 그라데이션이 한 번의 작업으로 줄어들고 Eager에서도 컴퓨팅/통신 중복이 발생하지 않습니다. 이 구성은 TorchDynamo에서 기능만 테스트한 것이지 성능은 테스트하지 않았습니다.
개발자/공급업체 경험
PyTorch 2.0에서는 백엔드(컴파일러) 통합 환경을 단순화하고자 합니다. 이를 위해 연산자 수를 줄이고 PyTorch 백엔드를 불러오는 데 필요한 연산자 집합의 의미를 단순화하는 데 중점을 두었습니다.
그래픽 형식으로 PT2 스택은 다음과 같습니다:
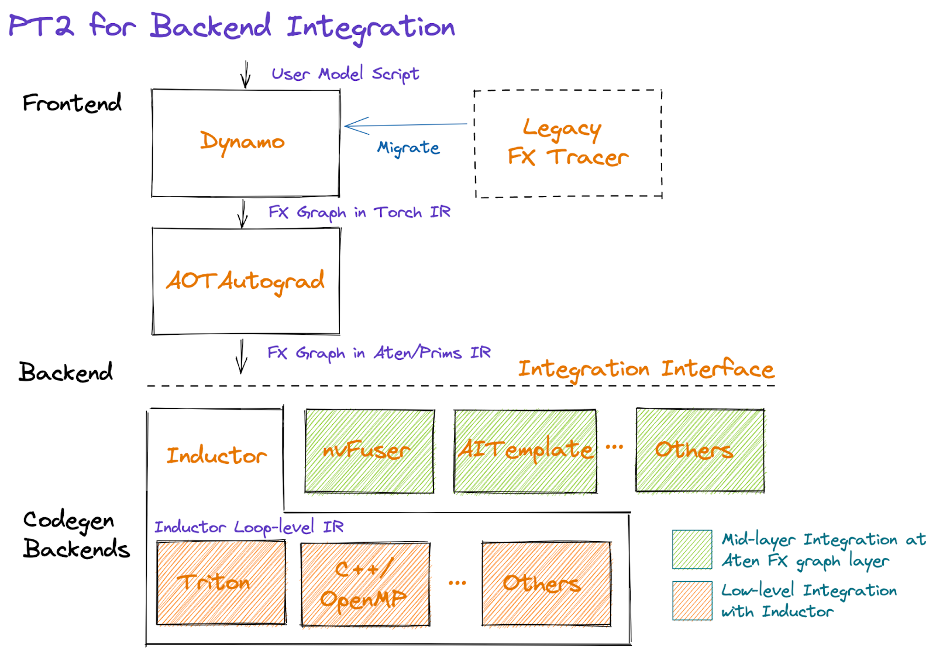
다이어그램의 중간부터 AOTAutograd는 오토그래드 로직을 동적으로 미리 캡처하여 FX 그래프 형식의 정방향 및 역방향 연산자 그래프를 생성합니다.
저희는 백엔드에서 구현해야 하는 연산자 수를 줄이기 위해 활용할 수 있는 일련의 강화된 분해(즉, 다른 연산자의 관점에서 작성된 연산자 구현)를 제공합니다. 또한 함수화라는 프로세스를 통해 돌연변이 및 뷰를 포함한 복잡한 PyTorch 로직을 선택적으로 재작성하고 모양 전파 공식과 같은 연산자 메타데이터 정보를 보장함으로써 PyTorch 연산자의 의미를 간소화합니다. 이 작업은 현재 활발히 진행 중이며, 우리의 목표는 공급업체가 통합을 간소화하기 위해 활용할 수 있는(즉, 옵트인할 수 있는) 단순화된 시맨틱을 갖춘 약 250개의 원시적이고 안정적인 연산자 집합인 PrimTorch를 제공하는 것입니다.
연산자 세트를 줄이고 단순화한 후, 백엔드는 다이나모(즉, 중간 계층, AOTAutograd 직후) 또는 인덕터(하위 계층)에서 통합을 선택할 수 있습니다. 아래에서 이러한 선택을 할 때 고려해야 할 사항과 백엔드 혼합에 대한 향후 작업 방법을 설명합니다.
Dynamo Backend
기존 컴파일러 스택을 보유한 벤더는 ATen/Prims IR 측면에서 FX 그래프를 수신하여 TorchDynamo 백엔드로 통합하는 것이 가장 쉬울 수 있습니다. 훈련과 추론 모두에서 통합 시점은 현재 AOTAutograd의 일부로 분해를 적용하고 추론을 타겟으로 하는 경우 역방향 특정 단계를 건너뛰기 때문에 AOTAutograd 직후가 될 것입니다.
Inductor backend
벤더는 백엔드를 인덕터에 직접 통합할 수도 있습니다. 인덕터는 ATen/Prim 연산으로 구성된 AOTAutograd에서 생성된 그래프를 가져와 루프 수준 IR로 더 낮춥니다. 현재 인덕터는 포인트, 감소, 분산/수집 및 윈도우 연산을 위해 루프 레벨 IR로 낮춰 제공합니다. 또한 인덕터는 효율적인 코드 생성을 지원하기 위해 퓨전 그룹을 생성하고, 인덱싱 단순화, 차원 축소, 루프 반복 순서를 조정합니다. 그런 다음 공급업체는 루프 레벨 IR에서 하드웨어별 코드에 대한 매핑을 제공하여 통합할 수 있습니다. 현재 인덕터에는 (1) 멀티스레드 CPU 코드를 생성하는 C++와 (2) 고성능 GPU 코드를 생성하는 Triton의 두 가지 백엔드가 있습니다. 이러한 인덕터 백엔드는 대체 백엔드를 위한 영감으로 사용할 수 있습니다.
혼합 백엔드 인터페이스(곧 출시 예정)
저희는 FX 그래프를 백엔드에서 지원하는 연산자를 포함하는 하위 그래프로 분할하고 나머지는 열심히 실행하는 유틸리티를 구축했습니다. 이러한 유틸리티는 '백엔드 혼합'을 지원하도록 확장할 수 있으며, 그래프의 어느 부분을 어떤 백엔드에서 실행할지 구성할 수 있습니다. 그러나 백엔드가 운영자 지원, 운영자 패턴에 대한 선호도 등을 노출할 수 있는 안정적인 인터페이스나 계약은 아직 없습니다. 이는 현재 진행 중인 작업으로, 얼리 어답터들의 피드백을 환영합니다.
최종 생각
파이토치 2.0과 그 이후의 방향에 대해 매우 기대가 됩니다. 최종 2.0 릴리스로 가는 길은 험난할 것이지만, 이 여정에 일찍부터 동참해 주세요. 더 자세히 알아보거나 컴파일러에 기여하는 데 관심이 있으시다면 시작 방법(예: 튜토리얼, 벤치마크, 모델, FAQ)에 대한 자세한 정보가 포함된 아래 글과 이번 달부터 시작되는 엔지니어에게 물어보세요: 2.0 라이브 Q&A 시리즈를 계속 읽어보시기 바랍니다. 추가 리소스는 다음과 같습니다: